Deep Reinforcement Learning
Dynamic Programming
Dynamic Programming (DP)
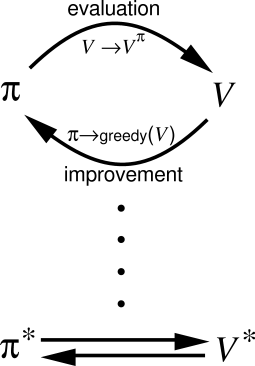
Dynamic Programming (DP) iterates over two steps:
Policy evaluation
- For a given policy \pi, the value of all states V^\pi(s) or all state-action pairs Q^\pi(s, a) is calculated based on the Bellman equations:
V^{\pi} (s) = \sum_{a \in \mathcal{A}(s)} \pi(s, a) \, \sum_{s' \in \mathcal{S}} p(s' | s, a) \, [ r(s, a, s') + \gamma \, V^{\pi} (s') ]
Policy improvement
- From the current estimated values V^\pi(s) or Q^\pi(s, a), a new better policy \pi is derived.
\pi' \leftarrow \text{Greedy}(V^\pi)
After enough iterations, the policy converges to the optimal policy (if the states are Markov).
Two main algorithms: policy iteration and value iteration.
Policy evaluation
- Bellman equation for the state s and a fixed policy \pi:
V^{\pi} (s) = \sum_{a \in \mathcal{A}(s)} \pi(s, a) \, \sum_{s' \in \mathcal{S}} p(s' | s, a) \, [ r(s, a, s') + \gamma \, V^{\pi} (s') ]
- Let’s note \mathcal{P}_{ss'}^\pi the transition probability between s and s' (dependent on the policy \pi) and \mathcal{R}_{s}^\pi the expected reward in s (also dependent):
\mathcal{P}_{ss'}^\pi = \sum_{a \in \mathcal{A}(s)} \pi(s, a) \, p(s' | s, a)
\mathcal{R}_{s}^\pi = \sum_{a \in \mathcal{A}(s)} \pi(s, a) \, \sum_{s' \in \mathcal{S}} \, p(s' | s, a) \ r(s, a, s')
The Bellman equation becomes V^{\pi} (s) = \mathcal{R}_{s}^\pi + \gamma \, \displaystyle\sum_{s' \in \mathcal{S}} \, \mathcal{P}_{ss'}^\pi \, V^{\pi} (s')
As we have a fixed policy during the evaluation (MRP), the Bellman equation is simplified.
Iterative policy evaluation
- The idea of iterative policy evaluation (IPE) is to consider a sequence of consecutive state-value functions which should converge from initially wrong estimates V_0(s) towards the real state-value function V^{\pi}(s).
V_0 \rightarrow V_1 \rightarrow V_2 \rightarrow \ldots \rightarrow V_k \rightarrow V_{k+1} \rightarrow \ldots \rightarrow V^\pi
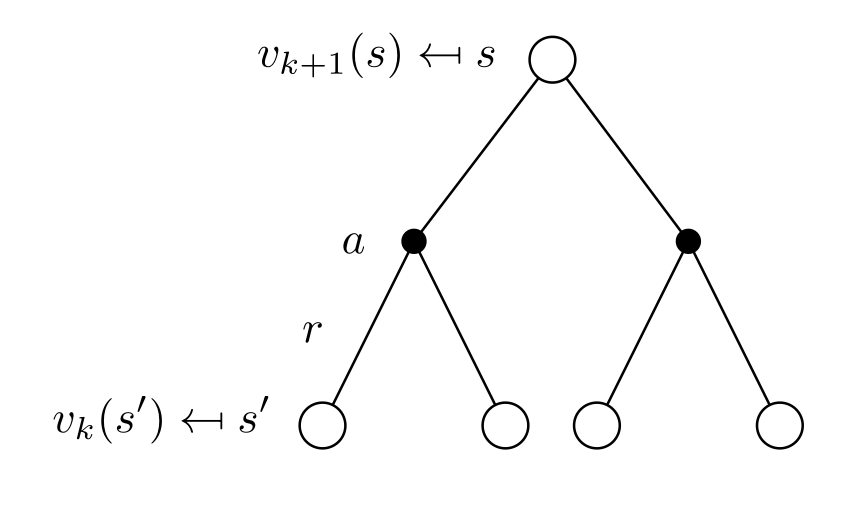
The value function at step k+1 V_{k+1}(s) is computed using the previous estimates V_{k}(s) and the Bellman equation transformed into an update rule.
In vector notation:
\mathbf{V}_{k+1} = \mathbf{R}^\pi + \gamma \, \mathcal{P}^\pi \, \mathbf{V}_k
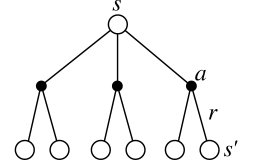
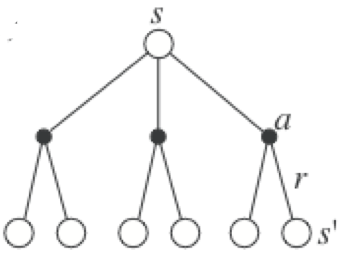
Backup diagram of IPE
- Iterative Policy Evaluation relies on full backups: it backs up the value of ALL possible successive states into the new value of a state.
V_{k+1} (s) \leftarrow \sum_{a \in \mathcal{A}(s)} \pi(s, a) \, \sum_{s' \in \mathcal{S}} p(s' | s, a) \, [ r(s, a, s') + \gamma \, V_k (s') ] \quad \forall s \in \mathcal{S}
- Backup diagram: which other values do you need to know in order to update one value?
- The backups are synchronous: all states are backed up in parallel.
\mathbf{V}_{k+1} = \mathbf{R}^\pi + \gamma \, \mathcal{P}^\pi \, \mathbf{V}_k
The termination of iterative policy evaluation has to be controlled by hand, as the convergence of the algorithm is only at the limit.
It is good practice to look at the variations on the values of the different states, and stop the iteration when this variation falls below a predefined threshold.
Dynamic Programming (DP)
Dynamic Programming (DP) iterates over two steps:
Policy evaluation
- For a given policy \pi, the value of all states V^\pi(s) or all state-action pairs Q^\pi(s, a) is calculated based on the Bellman equations:
V^{\pi} (s) = \sum_{a \in \mathcal{A}(s)} \pi(s, a) \, \sum_{s' \in \mathcal{S}} p(s' | s, a) \, [ r(s, a, s') + \gamma \, V^{\pi} (s') ]
Policy improvement
- From the current estimated values V^\pi(s) or Q^\pi(s, a), a new better policy \pi is derived.
Policy improvement
- For each state s, we would like to know if we should deterministically choose an action a \neq \pi(s) or not in order to improve the policy.
- The value of an action a in the state s for the policy \pi is given by:
Q^{\pi} (s, a) = \sum_{s' \in \mathcal{S}} p(s' | s, a) \, [r(s, a, s') + \gamma \, V^{\pi}(s') ]
- If the Q-value of an action a is higher than the one currently selected by the deterministic policy:
Q^{\pi} (s, a) > Q^{\pi} (s, \pi(s)) = V^{\pi}(s)
then it is better to select a once in s and thereafter follow \pi.
If there is no better action, we keep the previous policy for this state.
This corresponds to a greedy action selection over the Q-values, defining a deterministic policy \pi(s):
\pi(s) \leftarrow \text{argmax}_a \, Q^{\pi} (s, a) = \sum_{s' \in \mathcal{S}} p(s' | s, a) \, [r(s, a, s') + \gamma \, V^{\pi}(s') ]
Policy iteration
Once a policy \pi has been improved using V^{\pi} to yield a better policy \pi', we can then compute V^{\pi'} and improve it again to yield an even better policy \pi''.
The algorithm policy iteration successively uses policy evaluation and policy improvement to find the optimal policy.
\pi_0 \xrightarrow[]{E} V^{\pi_0} \xrightarrow[]{I} \pi_1 \xrightarrow[]{E} V^{\pi^1} \xrightarrow[]{I} ... \xrightarrow[]{I} \pi^* \xrightarrow[]{E} V^{*}
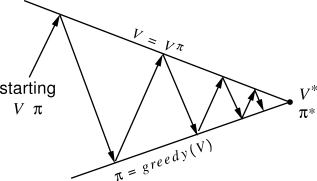
The optimal policy being deterministic, policy improvement can be greedy over the state values.
If the policy does not change after policy improvement, the optimal policy has been found.
Comparison of Policy- and Value-iteration
Full policy-evaluation backup
V_{k+1} (s) \leftarrow \sum_{a \in \mathcal{A}(s)} \pi(s, a) \, \sum_{s' \in \mathcal{S}} p(s' | s, a) \, [ r(s, a, s') + \gamma \, V_k (s') ]
Full value-iteration backup
V_{k+1} (s) \leftarrow \max_{a \in \mathcal{A}(s)} \sum_{s' \in \mathcal{S}} p(s' | s, a) \, [ r(s, a, s') + \gamma \, V_k (s') ]
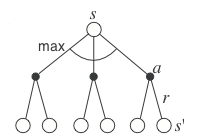
Efficiency of Dynamic Programming
Policy-iteration and value-iteration consist of alternations between policy evaluation and policy improvement, although at different frequencies.
This principle is called Generalized Policy Iteration (GPI).
Finding an optimal policy is polynomial in the number of states and actions: \mathcal{O}(n^2 \, m) (n is the number of states, m the number of actions).
However, the number of states is often astronomical, e.g., often growing exponentially with the number of state variables (what Bellman called “the curse of dimensionality”).
In practice, classical DP can only be applied to problems with a few millions of states.
Curse of dimensionality
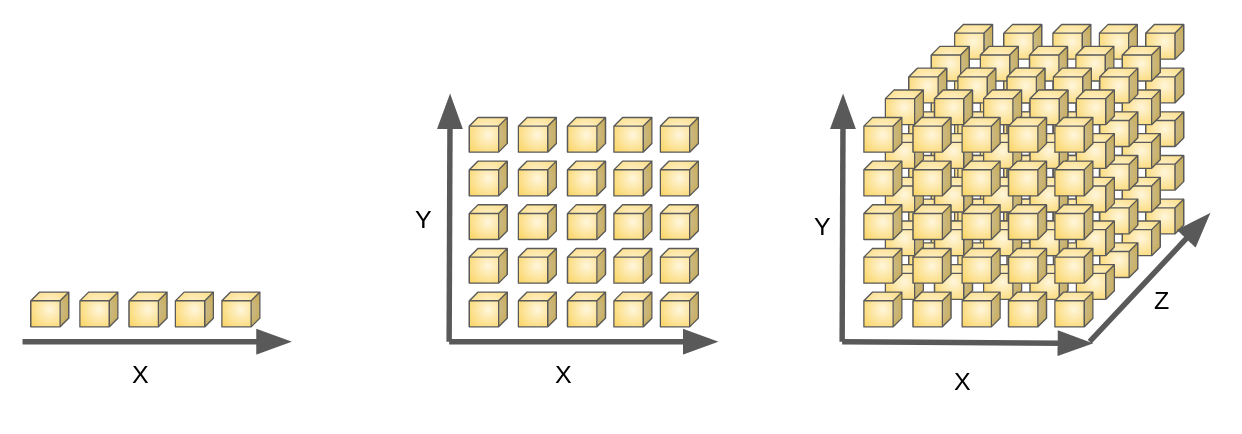
If one variable can be represented by 5 discrete values:
2 variables necessitate 25 states,
3 variables need 125 states, and so on…
The number of states explodes exponentially with the number of dimensions of the problem.